
안녕하세요, 리키입니다. 오늘은 인공지능 에이전트의 실수를 미리 막는 새로운 기술에 대한 흥미로운 이야기를 좀 해드리려고 합니다.
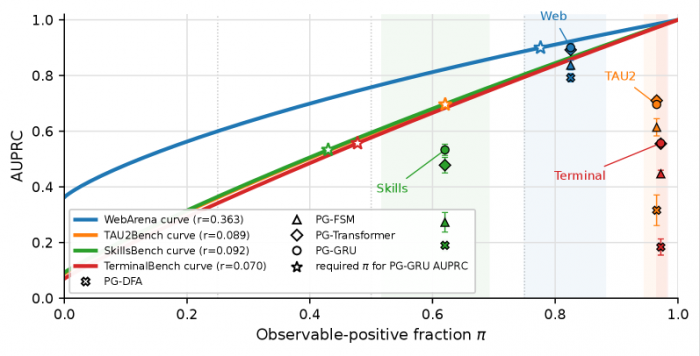
최근 영국과 프랑스의 연구진이 발표한 논문에서 아주 중요한 발견이 나왔습니다. 바로 AI 에이전트의 실패를 가장 정확하게 잡아내는 것이 거대 언어 모델(LLM)인 GPT 같은 큰 모델이 아니었다는 점입니다. 그들은 작고 가벼운 학습 모니터가 LLM 판사보다 최대 두 배 가까이 정확하게 에이전트의 실패를 예측해냈다고 보고했습니다. 이는 AI 에이전트가 복잡한 작업을 수행할 때 실시간으로 잘못된 방향으로 가는 순간을 감지하는 데 있어서 작은 모델이 훨씬 더 강력하다는 것을 의미합니다.
이러한 정확도를 높일 수 있었던 핵심 비결은 '스텝뷰(StepView)'라는 단계 표준화 기술에 있었습니다. AI 에이전트가 웹을 탐색하거나 명령을 내리는 과정은 기록 형식이 제각각인데, 스텝뷰는 이 모든 실행 기록을 일곱 가지 항목으로 통일시켜주는 변환기 역할을 합니다. 덕분에 연구진은 복잡한 변환 과정 없이도 비용을 거의 들이지 않으면서도, 실제 운영 환경에서 수천 건의 잘못된 행동을 미리 차단할 수 있는 수준의 성능을 달성할 수 있었더군요.
왜 작은 모델이 더 잘 작동했을까요? 그 이유는 비용과 시점의 차이 때문입니다. 거대 모델은 매 단계마다 호출할 때마다 비용과 시간이 많이 들어 실시간 감시에 적합하지 않았습니다. 반면, 작은 학습 모델은 실제로 실패한 수천 건의 작업 기록을 미리 학습했기 때문에, 실패 패턴을 빠르고 정확하게 파악하여 위험을 잡아낼 수 있었습니다. 즉, 거대한 추론 능력보다는 핵심 패턴을 짧은 기억 구조로 추적하는 것이 이 문제에는 더 적합했던 것이죠.
여기서 우리가 주목해야 할 또 다른 점이 있습니다. 가장 정확도가 높았던 모델이 반드시 실제 운영에서 가장 유용하다는 것은 아니라는 점입니다. 예를 들어, 웹아레나에서 가장 높은 점수를 받은 모델은 실패를 위험하다고 잘 정렬했지만, 실제 경보가 작동하는 능력은 상대적으로 약했습니다. 이는 점수가 높다는 것과 실제로 거짓 경보 없이 충분히 이른 시점에 신호를 보낸다는 것은 별개의 문제라는 것을 보여줍니다. 여러분, 단순히 정확도만 볼 것이 아니라, 실제 운영 환경에서의 경보 작동 능력까지 함께 봐야 한다는 통찰을 얻을 수 있었습니다.






'뉴스와 정보' 카테고리의 다른 글
| AI가 신의 자리를 위협한다 (0) | 2026.05.16 |
|---|---|
| 피지컬 AI가 이끈 로봇 산업 엔비디아 실적 폭발 (0) | 2026.05.16 |
| AI를 써도 바쁜 연구자의 현실 (0) | 2026.05.16 |
| 한국 자율주행 규제로 테슬라 기능 제한 (0) | 2026.05.16 |
| LLM 메모리 병목 해결할 PIM 반도체 개발 (0) | 2026.05.16 |