
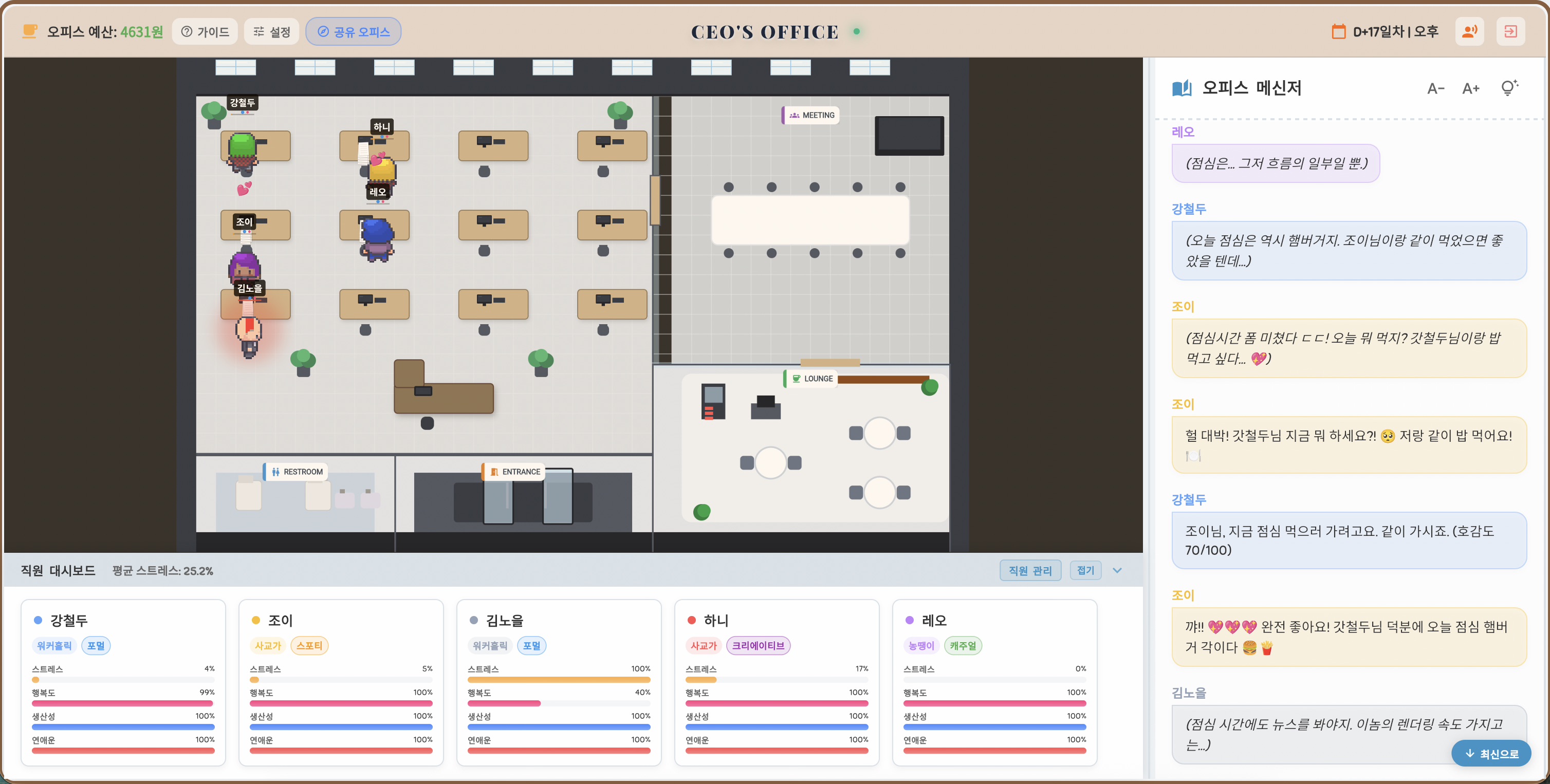
안녕하세요, 리키입니다. 오늘은 제가 'AI 오피스 시뮬레이션'을 만들면서 겪었던, LLM 비용 폭탄을 피하고 90%나 절감할 수 있었던 경험에 대해 이야기해 보려고 합니다. 처음에는 단순하게 시작했던 프로젝트였는데, 막상 운영해보니 비용이 예상보다 훨씬 빠르게 불어나는 끔찍한 구조를 발견하게 되었더군요.
처음에는 직원들(에이전트)이 대화할 때마다 실시간으로 LLM을 호출하는 구조였는데, 이게 비용 폭탄의 근본 원인이었습니다. 직원 10명이 하루 종일 대화를 나누면 API 비용이 생각보다 훨씬 빠르게 치솟는 것이죠. 특히, 직원 한 명이 말할 때마다 그 사람의 페르소나, 감정 수치, 이전 대화 기록, 관계 정보까지 모두 LLM에게 넘겨야 했고, 대화가 길어질수록 이 모든 정보(히스토리와 기억)가 기하급수적으로 늘어났습니다.
또 다른 문제는 아웃풋을 처리하는 방식이었습니다. 대화 내용이 JSON 형식으로 나오게 설정했는데, 실제 대화 내용은 한 줄인데 필드 이름이나 중괄호 같은 구조적인 정보가 내용보다 훨씬 많은 토큰을 차지했더군요. 이렇게 실시간으로 호출하는 방식은 비용을 통제하기가 매우 어려웠습니다. 저는 이 구조를 완전히 바꿔야겠다고 판단했습니다.
그래서 저는 아키텍처를 완전히 바꾸는 결정을 내렸습니다. 실시간으로 대화를 보여주는 것보다는 적절한 시점을 정해서 한 번에 대화를 생성하는 '배치 파이프라인' 방식으로 전환한 것입니다. 물론, 이 방식이 실시간성이 떨어진다는 단점도 있었지만, 비용을 절감하는 것이 더 중요하다고 생각했습니다. 이 과정에서 중요한 것은, 배치 방식으로 전환하더라도 직원들의 페르소나나 관계 같은 핵심적인 컨텍스트 정보는 그대로 LLM에게 전달된다는 점을 이해하는 것이었습니다.
결국 이 경험을 통해 저는 비용을 지불할 능력이 있는지 먼저 생각하고, 필요하지 않은 실시간 호출 대신 배치 처리를 선택하는 것이 현명하다는 것을 깨달았습니다. 여러분도 AI를 활용할 때, 단순히 기능 구현뿐만 아니라 그 뒤에 숨겨진 비용 구조와 데이터 처리 방식을 꼼꼼하게 따져보시는 것이 중요하다고 저는 생각합니다.
'뉴스와 정보' 카테고리의 다른 글
| 테슬라, 중국에 자율주행 서비스 확대 (0) | 2026.05.23 |
|---|---|
| NVIDIA Vera Rubin 에이전틱 AI 스케일업 과제 해결 (0) | 2026.05.23 |
| 아이비스 AI 차량 인포테인먼트 시스템 개발 참여 (0) | 2026.05.23 |
| 피지컬 AI 산업 전망 컨퍼런스 성료 (0) | 2026.05.23 |
| 현대모비스 SDV AI 전환 최대 수혜 전망 (0) | 2026.05.23 |