![]()
안녕하세요, 리키입니다. 오늘 제가 여러분과 이야기 나눌 주제는 아마도 요즘 기업들이 인공지능 에이전트 시스템을 운영할 때 겪는 문제와, 그걸 어떻게 안정적으로 해결하는지에 대한 이야기일 겁니다.
많은 회사들이 이제 대규모 언어 모델(LLM)을 기반으로 하는 에이전트 워크플로우를 실제 업무에 적용하고 있습니다. 그런데 이걸 프로덕션 규모로 키우다 보면, 모든 작업을 하나의 거대한 LLM에만 의존하는 방식의 한계가 드러나더군요. 에이전트가 도구를 분류하거나 요약하는 과정마다 동일한 토큰 비용이 계속 발생하고, 거대 모델이 응답하는 데 시간이 너무 오래 걸려서 실시간 대화에는 적합하지 않다는 문제가 생깁니다. 게다가 정확성이 중요한 업무에서는 환각(hallucination)의 위험도 있고, 민감한 데이터가 외부로 나가는 거버넌스 문제도 신경 써야 합니다.
이런 제약 때문에 우리는 하나의 결론에 도달하게 됩니다. 모든 작업에 거대한 LLM을 사용하는 방식은 장기적으로 지속 가능하지 않다는 것이죠. 그래서 복잡한 추론은 고성능 LLM이 담당하고, 반복적인 실무 작업(FAQ, 분류, 데이터 추출)은 도메인에 특화된 경량 모델, 즉 SLM(Small Language Model)이 담당하는 이질적인 다중 모델 생태계가 필요합니다. 연구 결과도 이를 뒷받침하는데, 에이전트 LLM 호출의 상당 부분은 파인튜닝된 SLM으로 대체할 수 있다는 것이죠.
이러한 다중 모델 환경을 효율적으로 운영하기 위해 쿠버네티스(Kubernetes) 생태계도 AI 네이티브 기능을 빠르게 확장하고 있습니다. 예를 들어, 게이트웨이 API를 통한 LLM 라우팅 표준화나 AI 워크로드 스케줄링 같은 기능들이 발전하고 있습니다. 그래서 우리는 Amazon EKS(Elastic Kubernetes Service) 기반의 오픈 아키텍처를 통해 이러한 다중 모델 운영을 위한 인프라 플랫폼으로 진화하고 있습니다.
운영 안정성을 위한 하이브리드 접근
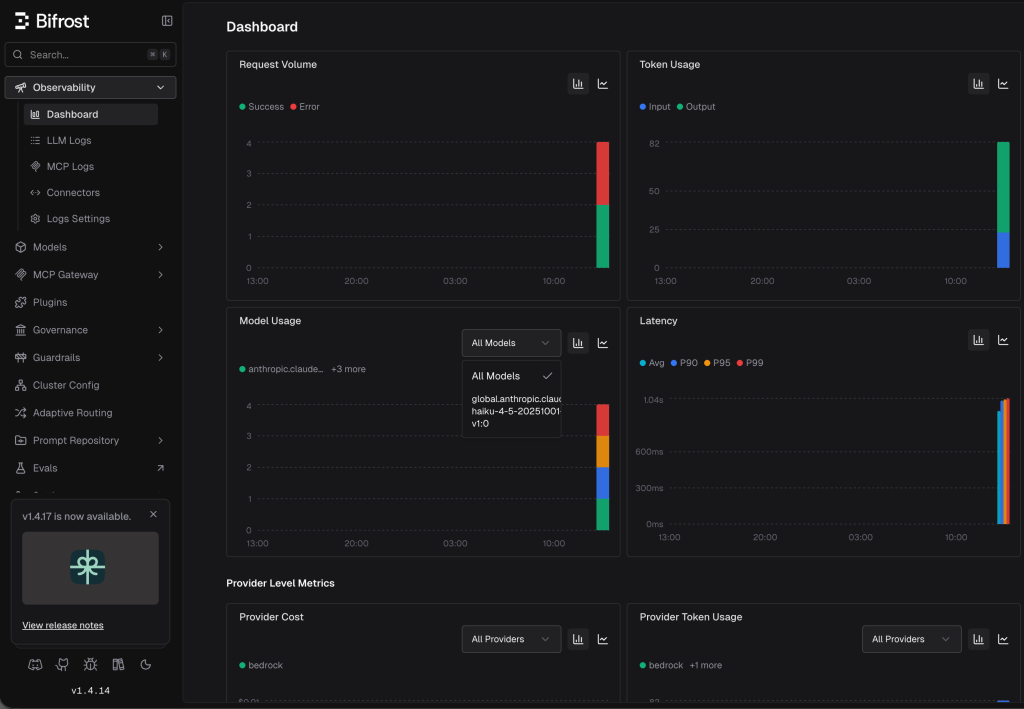
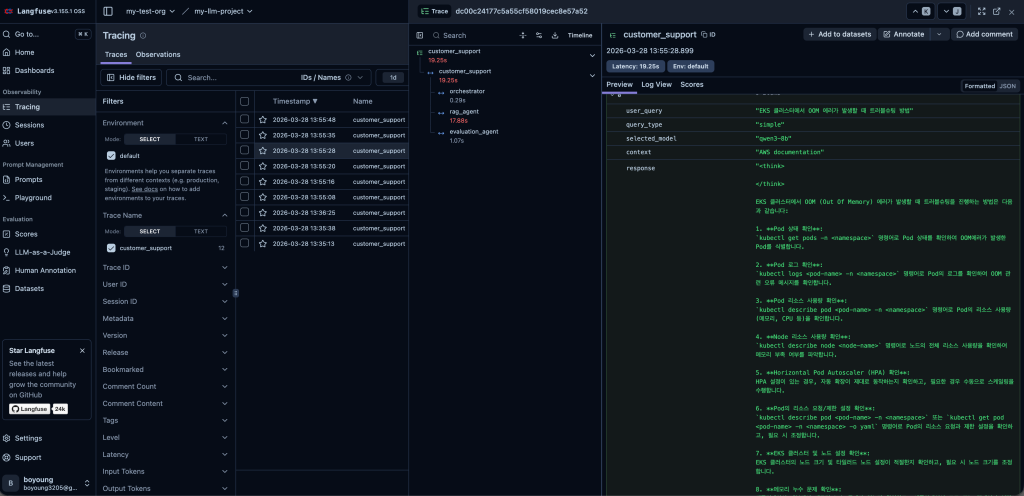
제가 제안하는 방법은 Amazon EKS Auto Mode를 활용하여 GPU 인프라를 자동화하고, Bifrost라는 게이트웨이를 통해 자체 호스팅 모델(예를 들어 vLLM)과 Amazon Bedrock을 하나의 엔드포인트로 통합하는 하이브리드 접근 방식입니다. 여기에 Langfuse를 활용하여 인프라 레벨과 애플리케이션 레벨의 두 가지 관측성(Observability)을 확보하는 것이 핵심입니다. EKS Auto Mode는 GPU 자원 관리를 자동화하고, Bifrost는 모델 간의 통합을 담당하며, Langfuse는 비용 효율성과 에이전트의 품질을 동시에 추적하게 해주는 것이죠.
결국 이 시스템은 인프라 비용을 최적화하는 것(모델 선택)과 에이전트의 품질을 최적화하는 것(에이전트 튜닝)을 동시에 수행할 수 있게 해줍니다. EKS Auto Mode를 통해 운영 부담을 줄이고 오픈소스의 유연성을 확보하면서, 복잡한 AI 시스템을 안정적으로 운영할 수 있는 것이 이 솔루션의 목표입니다. 여러분도 이 흐름을 이해하시면 앞으로의 AI 인프라 구축에 큰 도움이 될 거라 생각합니다.
![]()
참고 원문: https://aws.amazon.com/ko/blogs/tech/running-agentic-ai-platform-on-eks/
'뉴스와 정보' 카테고리의 다른 글
| AI발 대량 해고 빅테크 넘어 금융 유통까지 확대 (0) | 2026.05.12 |
|---|---|
| 서울시, 자체 LLM 구축 완료…생성형 AI 기반 '챗봇 2.0' 가동 (0) | 2026.05.12 |
| 알리바바 대화 쇼핑 AI 도입 (0) | 2026.05.12 |
| 128위안으로 차를 스마트콕핏으로 바꾸는 방법 (0) | 2026.05.12 |
| 테슬라, 기아 제치고 국내 전기차 1위 등극 (0) | 2026.05.12 |