안녕하세요, 리키입니다. 오늘은 대규모 환경에서 거대한 언어 모델(LLM)을 안정적으로 추론하는 것에 대해 이야기해 보려고 합니다. 이 분야는 단순히 기술적인 문제를 넘어, 우리가 일하고 생활하는 방식 자체가 변화하면서 얼마나 중요한지 말씀드릴 수 있겠군요.
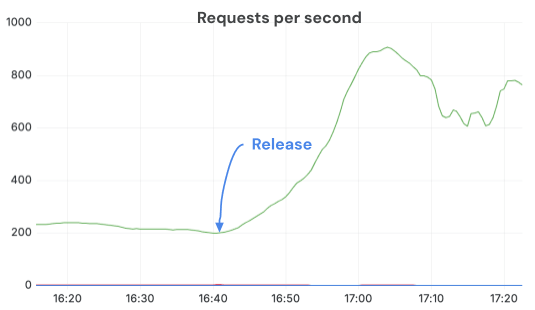
멀티테넌트 LLM 서빙을 하려면 워크로드 전체의 용량을 추론해야 합니다. 여기서 '모델 유닛'이라는 개념이 중요한데요, 이는 마치 고객별로 GPU 자원을 할당하고 확장할 수 있게 해주는 가상 머신(VM)과 비슷한 추상화라고 생각하시면 됩니다. 이 모델 유닛을 기반으로 로드 밸런싱과 자동 스케일링을 구현하면, 지연 시간 목표를 유지하면서도 기존 방식보다 GPU 비용을 80% 이상 절감할 수 있었더군요.
하지만 안정적인 추론 플랫폼을 구축하는 것은 쉽지 않습니다. 최신 성능을 위해서는 고대역폭 인터커넥트가 있는 최신 GPU가 필요하고, 이는 기존 CPU 시스템보다 훨씬 복잡하고 비용이 많이 듭니다. 특히 여러 노드 간의 통신이 필요하기 때문에, 시스템의 안정성을 확보하는 것이 매우 까다롭습니다. 단일 노드의 오류가 전체 서비스 중단으로 이어질 수 있는 상황을 막으려면, 분산 시스템의 표준적인 방법들을 활용해야 하는데, 이는 비용적인 부담을 안겨주기도 합니다.
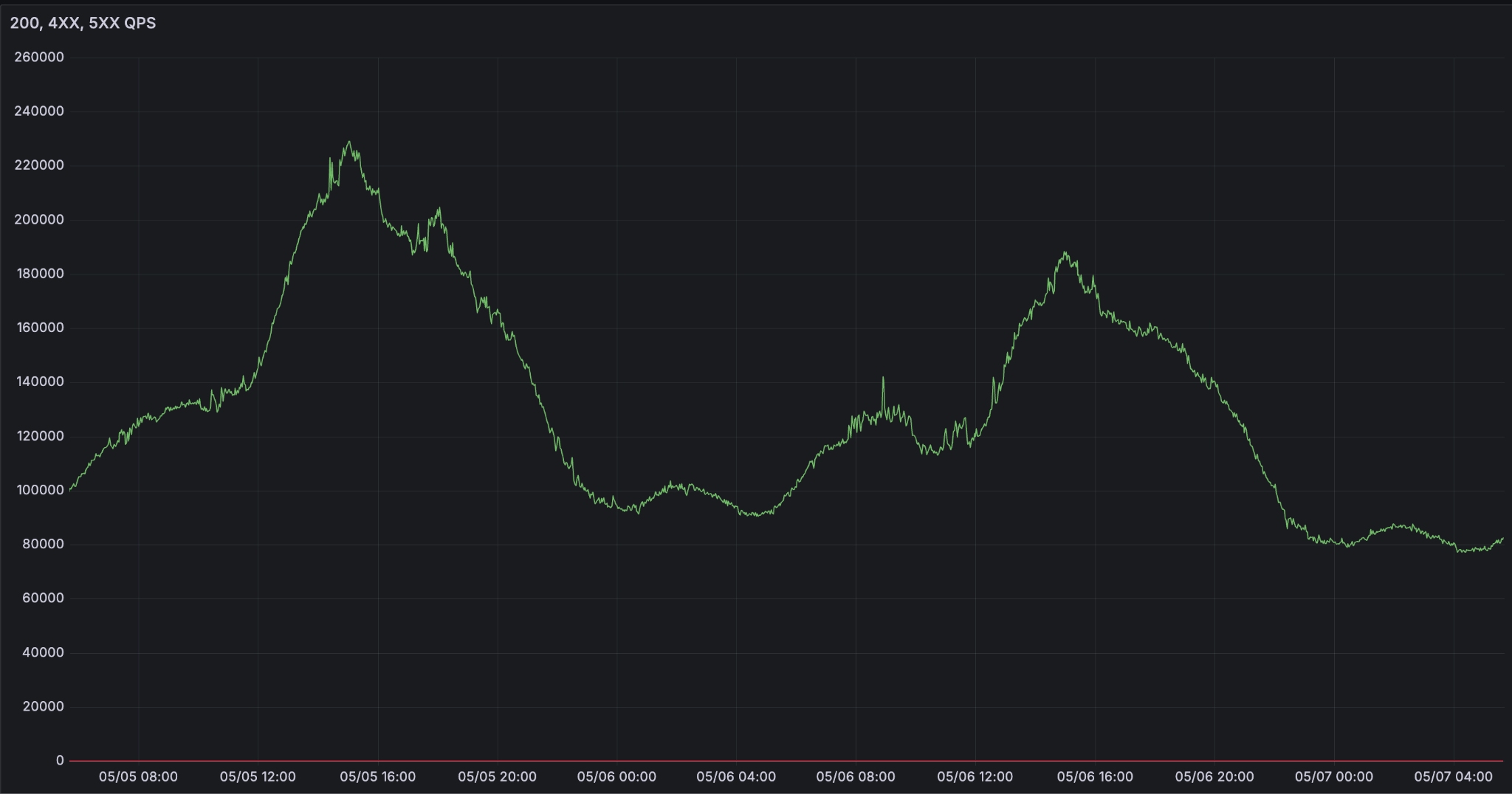
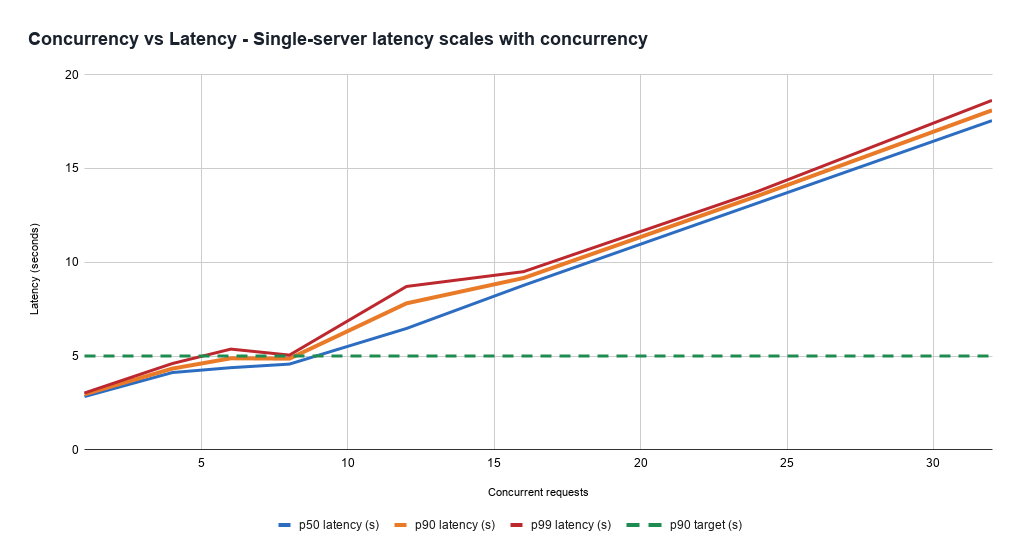
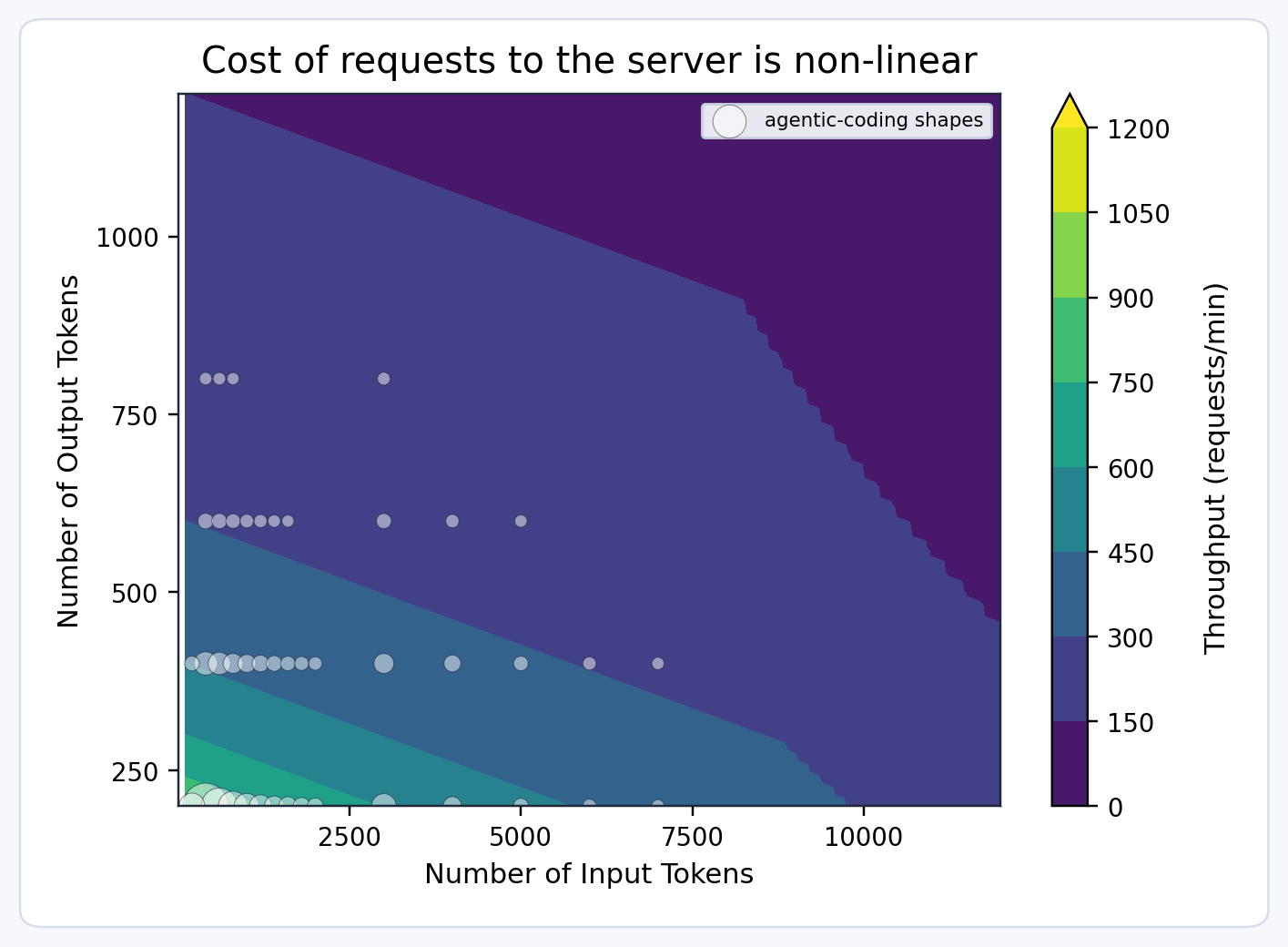
또한, 지연 시간 문제도 심각합니다. 다양한 부하 패턴에서 지연 시간을 제어하기가 어렵고, 요청 처리 비용이 예측하기 어렵기 때문입니다. 모델이 얼마나 오래 응답할지 예측하기 어렵다는 점 때문에, 낮은 지연 시간을 위해서는 복잡한 용량 관리와 로드 밸런싱 시스템이 필수적입니다. 단순히 처리량뿐만 아니라, 요청당 지연 시간과 안정성을 동시에 확보하는 것이 핵심 과제입니다.
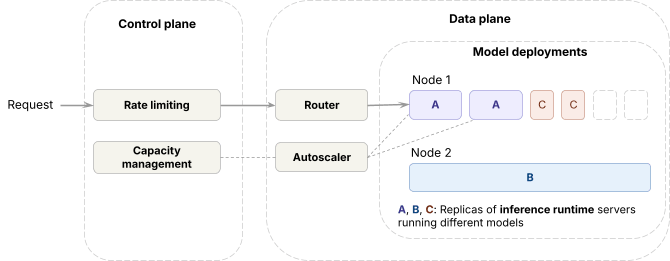
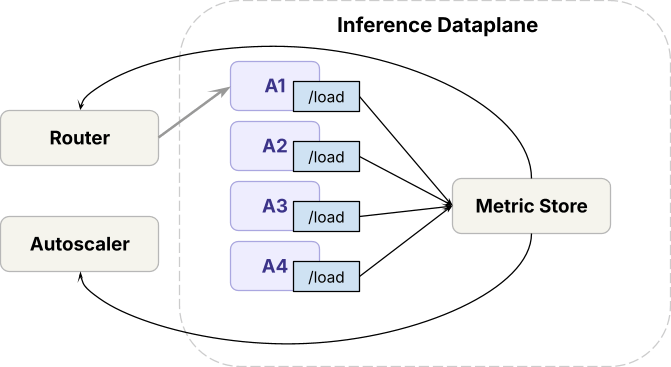
이러한 문제들을 해결하기 위해 시스템은 데이터 플레인과 컨트롤 플레인으로 나뉘어 작동합니다. 데이터 플레인에서는 추론 런타임과 라우터, 오토스케일러가 부하를 분산하고 복제본 수를 조정합니다. 컨트롤 플레인에서는 요청이 속도 제한을 거치고, 용량 관리 알고리즘이 GPU 용량을 결정하는 방식이죠. 우리는 '모델 유닛'이라는 추상화를 통해 이 복잡한 다차원적인 요청 비용을 모델링하고, 클라우드 VM처럼 예측 가능한 성능을 제공하는 방식으로 시스템을 분할하고 있습니다.
참고 원문: https://www.databricks.com/kr/blog/reliable-llm-inference-scale
'뉴스와 정보' 카테고리의 다른 글
| 유럽차 공장에 중국 경쟁사 유치 이유 (0) | 2026.05.31 |
|---|---|
| 농협은행, AI 기업과 직접투자 MOU 체결 (0) | 2026.05.31 |
| LG, 안드로이드 기반 차량용 멀티 스크린 공개 (0) | 2026.05.31 |
| SDV 시대 자동차 아키텍처 대전환 핵심은 전력반도체 (0) | 2026.05.31 |
| 피지컬 AI ETF 1년 수익률 141% 폭등 (0) | 2026.05.31 |